





摘要:,,本文探讨了凤凰网新闻爬虫的设计与应用的探讨。文章介绍了新闻爬虫的基本概念和工作原理,分析了凤凰网新闻爬虫的设计要点,包括数据抓取、数据存储、数据分析等方面。文章还探讨了新闻爬虫的应用场景,如数据挖掘、舆情分析、新闻报道等。文章总结了凤凰网新闻爬虫的应用价值和发展前景,强调了其在信息获取和分析领域的重要性。
本文目录导读:
随着互联网的普及和大数据时代的到来,新闻信息的获取和处理变得日益重要,凤凰网作为国内知名的新闻网站,其新闻内容的获取、整理与挖掘对于新闻工作者、研究人员以及广大网民具有重要意义,为此,设计一款针对凤凰网新闻的爬虫程序显得尤为重要,本文将详细介绍凤凰网新闻爬虫的设计思路、技术实现及应用价值。
凤凰网新闻爬虫设计概述
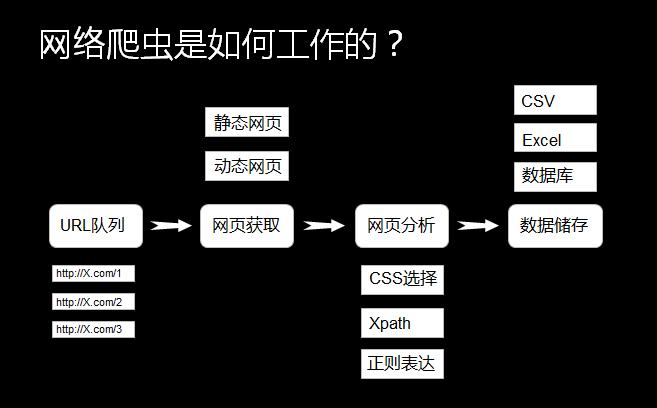
凤凰网新闻爬虫的设计旨在实现对凤凰网新闻内容的自动化获取、解析与存储,设计过程中需充分考虑目标网站的页面结构、反爬虫策略以及数据抓取效率等因素,以下是设计凤凰网新闻爬虫的主要步骤:
1、目标网站分析:了解凤凰网新闻页面的结构、数据组织形式以及反爬虫机制,为后续的数据抓取提供基础。
2、数据抓取策略制定:根据目标网站的分析结果,制定合适的数据抓取策略,包括URL请求、页面解析、数据提取等。
3、技术选型:根据设计需求,选择合适的技术和工具,如Python编程语言、Scrapy框架等。

4、爬虫架构搭建:根据数据抓取策略和技术选型,搭建爬虫的架构,包括数据请求模块、页面解析模块、数据存储模块等。
技术实现细节
1、数据请求模块:采用Python的requests库实现HTTP请求,获取凤凰网新闻页面的HTML代码。
2、页面解析模块:利用BeautifulSoup库对HTML代码进行解析,提取新闻标题、内容、时间等关键信息。
3、反爬虫策略应对:针对凤凰网的反爬虫策略,采用动态调整请求头、设置延迟等措施,提高爬虫的稳定性。
4、数据存储模块:将抓取到的新闻数据存储在本地数据库或云端,方便后续的数据处理和分析。

凤凰网新闻爬虫的应用价值
凤凰网新闻爬虫的应用价值主要体现在以下几个方面:
1、新闻信息获取:实现自动化获取凤凰网新闻内容,提高信息获取效率。
2、数据挖掘与分析:通过对抓取到的新闻数据进行挖掘和分析,发现新闻背后的规律和趋势,为决策提供支持。
3、舆情监测:利用爬虫技术实现对凤凰网新闻的实时监测,为舆情分析提供数据支持。
4、个性化推荐:根据用户的兴趣和需求,利用爬虫技术获取相关领域的新闻内容,实现个性化推荐。
案例分析
以某企业为例,该企业利用凤凰网新闻爬虫技术实现对行业新闻的实时监测和挖掘,通过抓取凤凰网上关于该行业的新闻报道,分析行业发展趋势、竞争对手动态等信息,为企业决策提供支持,根据企业内部的个性化需求,对特定领域的新闻进行推荐,提高员工的工作效率。
本文详细阐述了凤凰网新闻爬虫的设计思路、技术实现以及应用价值,通过实际应用案例,展示了凤凰网新闻爬虫在新闻信息获取、数据挖掘与分析、舆情监测以及个性化推荐等方面的价值,随着技术的不断发展,未来凤凰网新闻爬虫将在更多领域得到应用,为各行各业提供更有价值的数据支持。
 赣ICP备2020014130号-1
赣ICP备2020014130号-1 赣ICP备2020014130号-1
赣ICP备2020014130号-1
还没有评论,来说两句吧...